NixOS: ASBR mit VRF zur Separierung von EGP und IGP¶
In unserem Netzwerk betreiben wir einen ASBR (Autonomous System Boundary Router) auf Basis von NixOS, ifstate und FRRouting. Ziel war es, das EGP (Exterior Gateway Protocol) und das IGP (Interior Gateway Protocol) mittels einer VRF (Virtual Routing and Forwarding) voneinander zu trennen.
Der grundsätzliche Aufbau wird durch das folgende Schaubild beschrieben:
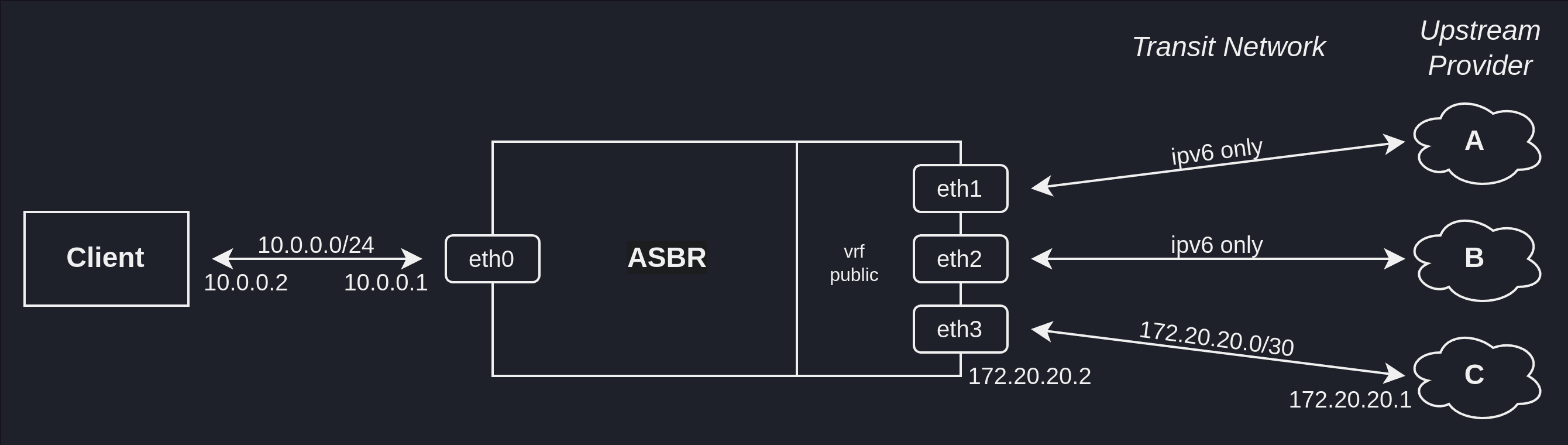
Zum Testen der Konfiguration wurde ein Client direkt an den ASBR angebunden. Dieser Client ist Teil des internen Netzwerks, gehört somit zum IGP und ist über die Schnittstelle eth0 verbunden, welche der Global Routing Table (GRT bzw. rttable main) zugewiesen ist. In dieser Tabelle wurde eine Default-Route konfiguriert, die den Traffic über die VRF public leitet.
An die VRF public wiederum sind drei Upstream-Provider angebunden: A, B und C. Während die Provider A und B jeweils eine vollständige IPv6-Routingtabelle (auch als Default-Free Zone (DFZ) bekannt) bereitstellen, delegiert Upstream Provider C zusätzlich einige IPv4 Adressen in Form eines PA (Provider Aggregatable) Assignment. Anders als die beiden anderen Upstream Provider liefert C jedoch keine vollständige Routingtabelle, sondern lediglich eine Default-Route per BGP (default-originate).
In diesem Blog-Artikel dient die öffentliche IPv4 12.34.56.78 als Beispieladresse aus dem delegierten Netzwerk.
Nachdem die Implementierung durchgeführt wurde, wurde getestet, ob diese wie erwartet funktioniert. Zunächst wurde getestet, ob das ASBR selbst mit dem Internet kommunizieren kann:
[root@asbr:~]# ping -c 1 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=57 time=28.6 ms
--- 1.1.1.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 28.909/28.909/28.909/0.000 ms
[root@asbr:~]# tcpdump -n -i any icmp
00:00:00.031238 public Out IP 12.34.56.78 > 1.1.1.1: ICMP echo request, id 3, seq 1, length 64
00:00:00.031252 eth3 Out IP 12.34.56.78 > 1.1.1.1: ICMP echo request, id 3, seq 1, length 64
00:00:00.059831 eth3 In IP 1.1.1.1 > 12.34.56.78: ICMP echo reply, id 3, seq 1, length 64
Nachdem dies erfolgreich war, wurde geprüft, ob der Client ebenfalls eine Verbindung aufbauen kann:
[root@client:~]# ping -c 4 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
--- 1.1.1.1 ping statistics ---
4 packets transmitted, 0 received, 100% packet loss, time 3072ms
[root@asbr:~]# tcpdump -n -i any icmp
00:00:00.004049 eth0 In IP 10.0.0.2 > 1.1.1.1: ICMP echo request, id 53, seq 1, length 64
00:00:00.004049 eth0 In IP 10.0.0.2 > 1.1.1.1: ICMP echo request, id 53, seq 2, length 64
00:00:00.004049 eth0 In IP 10.0.0.2 > 1.1.1.1: ICMP echo request, id 53, seq 3, length 64
00:00:00.004049 eth0 In IP 10.0.0.2 > 1.1.1.1: ICMP echo request, id 53, seq 4, length 64
Wie aus den tcpdump-Ausgaben ersichtlich ist, werden nur die eingehenden ICMP Echo-Requests vom Client protokolliert. Es findet jedoch keine Weiterleitung in der VRF public oder auf dem Interface eth3 (zum Upstream-Provider C) statt.
Um das Problem besser untersuchen zu können, entschied ich mich einen NixOS Integration Test für das Szenario anzulegen. Im ersten Schritt implementierte ich lediglich IPv6 mit den Upstream Providern A und B, welche uns beide eine Full Table zur Verfügung stellen. Nachdem dies funktionierte, fügte ich IPv4 und den Upstream Provider C hinzu. Dabei war feststellbar, dass neben IPv4 auch IPv6 nicht mehr funktionierte. Ich versuchte verschiedene Konfigurationen zu implementieren. Irgendwann deaktivierte ich die von Upstream Provider C announcte Default-Route, was dazu führte, dass IPv6 wieder wie gewünscht funktionierte.
Basierend auf den gewonnenen Erkenntnissen beschlossen wir, die von Upstream-Provider C per BGP announcierte Default-Route herauszufiltern. Dazu modifizierten wir in FRR die Prefix-List, die beim Import der Routen von Provider C greift um das entsprechende Präfix zu blockieren.
Für IPv4 relevante Ausschnitte der FRR Konfiguration und Überprüfung ob Konfiguration zum gewünschten Ergebnis führt
Die erste Zeile sorgt, dafür dass die Default Route abgelehnt wird:ip prefix-list import seq 1 deny 0.0.0.0/0
ip prefix-list import seq 2 permit 0.0.0.0/0 le 32
ip prefix-list export seq 1 permit 12.34.56.78/32
ip prefix-list export seq 2 deny 0.0.0.0/0 le 32
!
ip route 12.34.56.78/32 Null0
!
vrf public
ip protocol bgp route-map set-src
exit-vrf
!
router bgp OWN_ASN vrf public
bgp router-id 12.34.56.78
no bgp default ipv4-unicast
no bgp network import-check
neighbor 172.20.20.1 remote-as ASN_UPSTREAM_C
!
address-family ipv4 unicast
network 12.34.56.78/32
neighbor 172.20.20.1 activate
neighbor 172.20.20.1 remove-private-AS
neighbor 172.20.20.1 soft-reconfiguration inbound
neighbor 172.20.20.1 prefix-list import in
neighbor 172.20.20.1 prefix-list export out
exit-address-family
exit
!
route-map set-src permit 1
set src 12.34.56.78
exit
[root@asbr:~]# vtysh -c 'show ip bgp vrf public neighbors 172.20.20.1 received-routes'
BGP table version is 2, local router ID is 12.34.56.78, vrf id 7
Default local pref 100, local AS OWN_ASN
Status codes: s suppressed, d damped, h history, u unsorted, * valid, > best, = multipath,
i internal, r RIB-failure, S Stale, R Removed
Nexthop codes: @NNN nexthop's vrf id, < announce-nh-self
Origin codes: i - IGP, e - EGP, ? - incomplete
RPKI validation codes: V valid, I invalid, N Not found
Network Next Hop Metric LocPrf Weight Path
*> 0.0.0.0/0 172.20.20.1 0 ASN_UPSTREAM_C i
Total number of prefixes 1 (1 filtered)
[root@asbr:~]# vtysh -c 'show ip bgp vrf public neighbors 172.20.20.1 routes'
Anschließend überprüften wir die Konnektivität erneut, indem wir vom Client aus gezielt die IPv4-Adresse des Transit-Netzes von Provider C anpingten.
Warum sollte das funktionieren?
Das Interface eth3 ist in der VRF public mit einer IPv4-Konfiguration versehen. Da es sich dabei um ein /30er-Netz handelt, wird automatisch eine "connected" bzw. Kernel-Route für dieses Subnetz erzeugt. Diese Route ist auch ohne weitere BGP-Routen innerhalb der VRF verfügbar und ermöglicht daher gezielt die Erreichbarkeit der Transit-Adresse des Upstream-Providers.Routen in FIB für VRF public anzeigen:
[root@asbr:~]# ip route show vrf public
172.20.20.0/30 dev eth3 proto kernel scope link src 172.20.20.2
Routen in RIB für VRF public anzeigen:
[root@asbr:~]# vtysh -c 'show ip route vrf public'
Codes: K - kernel route, C - connected, L - local, S - static,
R - RIP, O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
T - Table, v - VNC, V - VNC-Direct, A - Babel, D - SHARP,
F - PBR, f - OpenFabric, t - Table-Direct,
> - selected route, * - FIB route, q - queued, r - rejected, b - backup
t - trapped, o - offload failure
VRF public:
L * 12.34.56.78/32 is directly connected, public, 00:00:00
C>* 12.34.56.78/32 is directly connected, public, 00:00:00
C>* 172.20.20.0/30 is directly connected, eth3, 00:00:00
L>* 172.20.20.2/32 is directly connected, eth3, 00:00:00
[root@client:~]# ping -c 1 172.20.20.2
PING 172.20.20.2 (172.20.20.2) 56(84) bytes of data.
64 bytes from 172.20.20.2: icmp_seq=1 ttl=63 time=33.3 ms
--- 172.20.20.2 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 33.285/33.285/33.285/0.000 ms
[root@asbr:~]# tcpdump -n -i any icmp
00:00:00.730500 eth0 In IP 10.0.0.2 > 172.20.20.2: ICMP echo request, id 24, seq 19, length 64
00:00:00.730540 public Out IP 10.0.0.2 > 172.20.20.2: ICMP echo request, id 24, seq 19, length 64
00:00:00.730567 eth3 Out IP 12.34.56.78 > 172.20.20.2: ICMP echo request, id 24, seq 19, length 64
00:00:00.746948 eth3 In IP 172.20.20.2 > 12.34.56.78: ICMP echo reply, id 24, seq 19, length 64
00:00:00.746991 eth0 Out IP 172.20.20.2 > 10.0.0.2: ICMP echo reply, id 24, seq 19, length 64
Es darf also keine Default Route innerhalb der VRF verwendet werden, da sonst das Forwarding beeinträchtigt wird.
Ohne Default-Route wird ein Paket vom Client wie folgt durch den ASBR geleitet.
[root@asbr:~]# ip rule
0: from all lookup local
1000: from all lookup [l3mdev-table]
32766: from all lookup main
32767: from all lookup default
Zunächst greift die lookup local-Policy - diese wird aber übersprungen, da das Ziel keine lokale
Adresse ist. Auch die Regel lookup [l3mdev-table] wird anfangs übersprungen, weil das Paket aus
der GRT (IGP) stammt und somit keinen VRF-Kontext hat. Schließlich gelangt das Paket zur Regel
lookup main. Die FIB der GRT beinhaltet eine Default-Route, die das Paket in die VRF public
routet. Innerhalb dieser gibt es eine Connected/Kernel Route, die das Paket über eth3 an Upstream
Provider C weiterleitet. Dabei wird das Paket ebenfalls auf die öffentliche IPv4 Adresse genattet.
Eine Default-Route in der FIB der VRF Public sorgt für zwei Probleme:
-
Aus unbekannten Gründen erfolgt kein Forwarding von Paketen aus der GRT. Auch mittels tcpdump war nicht nachvollziehbar, ob das Forwarding von der GRT in die VRF public oder von VRF public zu Upstream Provider C fehlschlägt und dies falsch in tcpdump dargestellt wird.
-
Wird ein Paket aus eth3 (Upstream Provider C) empfangen, hat dieses einen VRF Kontext, wodurch nach der
lookup local-Policy die Regellookup [l3mdev-table]zutrifft. Dadurch wird in der FIB der VRF public nach einer passenden Route zum Ziel gesucht. Diese wird in Form der Default-Route gefunden, wodurch das Paket sofort zurück zum Upstream Provider C geschickt wird. Es findet also keinlookup mainstatt.
Da wir von den delegierten Adressen des Upstream Providers C abhängig sind, musste eine Lösung für dieses Problem gefunden werden. Da sich diese Abhängigkeit ausschließlich auf IPv4 bezieht, wurde zunächst die IPv6-BGP-Sitzung deaktiviert. Im Anschluss wurden die notwendigen IPv4-Routen (0.0.0.0/0 ohne Bogon-Präfixe) generiert und statisch in der FIB der VRF public definiert:
from netaddr import IPSet
result = IPSet(["0.0.0.0/0"]) - IPSet([
"0.0.0.0/8",
"10.0.0.0/8",
"100.64.0.0/10",
"127.0.0.0/8",
"169.254.0.0/16",
"172.16.0.0/12",
"192.0.0.0/24",
"192.0.2.0/24",
"192.168.0.0/16",
"198.18.0.0/15",
"198.51.100.0/24",
"203.0.113.0/24",
"224.0.0.0/4",
"240.0.0.0/4",
"255.255.255.255/32",
])
print('\n'.join([str(cidr) for cidr in result.iter_cidrs()]))
Anschließend funktionierte auch die Kommunikation zwischen Client und Internet:
[root@client:~]# ping -c 1 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=63 time=35.2 ms
--- 1.1.1.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 33.285/33.285/33.285/0.000 ms
[root@asbr:~]# tcpdump -n -i any icmp
00:00:00.730500 eth0 In IP 10.0.0.2 > 1.1.1.1: ICMP echo request, id 24, seq 19, length 64
00:00:00.730540 public Out IP 10.0.0.2 > 1.1.1.1: ICMP echo request, id 24, seq 19, length 64
00:00:00.730567 eth3 Out IP 12.34.56.78 > 1.1.1.1: ICMP echo request, id 24, seq 19, length 64
00:00:00.746948 eth3 In IP 1.1.1.1 > 12.34.56.78: ICMP echo reply, id 24, seq 19, length 64
00:00:00.746991 eth0 Out IP 1.1.1.1 > 10.0.0.2: ICMP echo reply, id 24, seq 19, length 64
Unsere weitere Absicht ist es, bei Upstream Provider C nach einer Full Table zu fragen. Aus meiner Sicht ist die Verwendung von default-originate für ein öffentliches Peering grundsätzlich unzweckmäßig. Der Grund dafür ist, dass nur Pakete über diese Route geleitet werden, die nicht in den Routing-Tabellen der anderen Provider enthalten sind. Kürzere Routen, die über Provider C verfügbar wären, können nicht erkannt werden und werden deshalb weiterhin über den längeren Pfad geroutet.